On the excellent blog of Troy Hunt you can read how he’s using Azure webjobs to process leaked user account dumps. As with anything in IT, there are many solutions to a problem. Lately I’ve been busy with Azure event hubs, streaming analytics and HDInsight, I thought it would be a nice experiment to use the same data dump but process it in an entirely different manner. In this first post, I’ll illustrate the data input part. In a follow-up post, I’ll use HDInsight to process the actual data.
The data source that has to be processed is a 5,12 GB text file containing 100 million email addresses which I uploaded to blob storage. Just like Troy I then created a batching solution to process the file in chuncks. I didn’t want to use webjobs so instead I created a cloud service. This service reads line numbers from a queue. The line numbers indicate which lines to read from the text file and send to the event hub.

The code in the cloud service is pretty straightforward. Open a filereader and move to the line number which is indicated in the incoming message from queue storage. Then start reading the lines of the file that need to be processed and fire away at the event hub. I have not given the code much thought, so there are probably several ways this can be improved, I just wanted to get up and running. The event hub receives json objects containing the name of the website and the email address.
using (var streamReader = new StreamReader(file.OpenRead()))
{
int row = 0;
while (row < beginAt)
{
streamReader.ReadLine();
row++;
}
while (row <= endAt)
{
row++;
var line = streamReader.ReadLine();
lines.Add(line);
}
Parallel.ForEach(lines, line => {
var leakedEmail = JsonConvert.SerializeObject(new { leak = "websitesource", address = line });
eventHubClient.Send(new EventData(Encoding.UTF8.GetBytes(leakedEmail)));
});
} |
using (var streamReader = new StreamReader(file.OpenRead()))
{
int row = 0;
while (row < beginAt)
{
streamReader.ReadLine();
row++;
}
while (row <= endAt)
{
row++;
var line = streamReader.ReadLine();
lines.Add(line);
}
Parallel.ForEach(lines, line => {
var leakedEmail = JsonConvert.SerializeObject(new { leak = "websitesource", address = line });
eventHubClient.Send(new EventData(Encoding.UTF8.GetBytes(leakedEmail)));
});
}
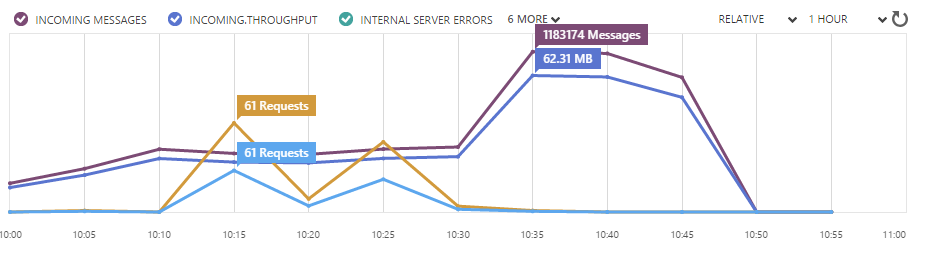
I created batches of 1 million rows which means 100 batches that had to be processed. I deployed the service and then observed the system. After seeing one instance running correctly I scaled up the system to get 20 instances running simultaneous.

The result was already quite nice. All of the instances together were sending around 4,2 million leaked email addresses every 5 minutes with a peak of 4.5 million at the end.

This meant that in under two hours the entire file had been sent into my event hub. 
Between 12 and 1 PM I only had one instance running. I scaled up somewhere between 1 and 2 PM.
What did this cost?
- Running 20 A1 instances of a cloud service: ~ €3,5
- Receiving 100 million event hub request (and doing some processing): ~ €2
In the next post I’ll show you the HDInsight part which will take every event from the event hub and insert or update the address in table storage.